Extracting Text from an Image with Amazon Textract and .NET
Want to learn more about AWS Lambda and .NET? Check out my A Cloud Guru course on ASP.NET Web API and Lambda.
Download full source code.
Extracting text from an image is a common task for many applications. In this and the next few blog posts, I’ll show how to do this with the Textract service on AWS. It requires no machine learning/artificial intelligence expertise, and there is no infrastructure to set up. You use an SDK to call the service, passing the image to analyze. The response contains the text extracted from the image.
This first post will extract text from a single image, the first page of a book.
I use Blazor, to load the image, send it to Textract, display the image on the page, and display the extracted text. Keep in mind when looking at the code that my Blazor skills are pretty limited.
The reason to upload the file to the web server rather than just sending it directly to Textract is to allow me to display the image on the page before processing it (by default, you can’t serve a file that lies outside of the wwwroot folder).
The attached zip has the full source code, so I won’t go through it all here, instead, I’ll show only the Textract parts.
Using Textract
Create the client -
private IAmazonTextract textractClient = new AmazonTextractClient();
private DetectDocumentTextResponse? detectDocumentResponse;In a follow-up post, I show how to use Dependency Injection to create the client.
Send the uploaded image to Textract -
1processingMessage = $"Working on file {sourceImage.Name}...";
2FileStream fileStream = new FileStream(uploadedFilePath, FileMode.Open, FileAccess.Read);
3MemoryStream memoryStream = new MemoryStream();
4await fileStream.CopyToAsync(memoryStream);
5await fileStream.FlushAsync();
6Amazon.Textract.Model.Document document = new Document
7{
8 Bytes = memoryStream
9};
10var detectDocumentTextRequest = new DetectDocumentTextRequest()
11{
12 Document = document
13};
14detectDocumentResponse = await textractClient.DetectDocumentTextAsync(detectDocumentTextRequest);detectDocumentResponse contains the extracted text.
I use some simple Blazor code to display the extracted text beside the source image.
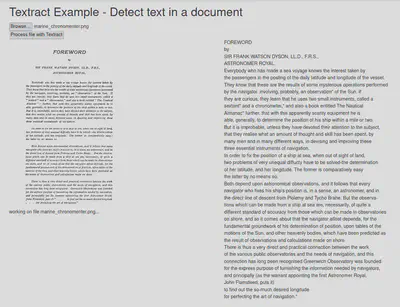
Conclusion
Getting started with Textract is easy, but it can do much more than just extracting text from an image.
In follow-up posts, I’ll show some other fun and useful things you can do with Textract.
Download full source code.