Extracting Key-Value Pairs from Document Form Fields with Amazon Textract and .NET
Want to learn more about AWS Lambda and .NET? Check out my A Cloud Guru course on ASP.NET Web API and Lambda.
Download full source code.
In my previous post, I showed how to extract text from an image using Textract. Each line in the image was extracted to a line of text and displayed on the screen. That is very useful for scenarios where you are processing blocks of text, or where you want all the text on an image but are not concerned about the structure of the text.
In this post, I will show how to extract text from a form. The form is in an image. The form I will use is a W-2 tax form, common in the US. The various fields will be extracted to key-value pairs. Keep in mind this is a demo, and there are some limitations in the code - duplicated keys are removed, as are keys without values.
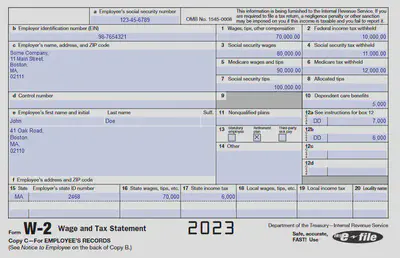
If you want to know more about the process for extracting key-value pairs from a form, see the Textract documentation.
Like the previous post, I use Blazor to load the form and display the extracted key-value pairs. My Blazor skills are limited, so don’t copy/paste the code.
The attached zip has the full source code, so I won’t go through it all here, instead, I’ll show some of the Textract parts.
Using Textract
In the previous post, I created the Textract client directly, but in this, I use dependency injection.
@inject IAmazonTextract TextractClient;As before, I upload the image to the server, so I can display it on the page before sending it to Textract. See the attached zip for this code.
Then I send that file to Textract for processing. Because I am sending a single image the call to Textract will wait for a response. In a future post, I will send a document with multiple pages, in that case, a job id is returned, and the client needs to poll for the results.
1FileStream fileStream = new FileStream(uploadedFilePath, FileMode.Open, FileAccess.Read);
2MemoryStream memoryStream = new MemoryStream();
3
4await fileStream.CopyToAsync(memoryStream);
5await fileStream.FlushAsync();
6
7var analyzeDocumentRequest = new AnalyzeDocumentRequest()
8{
9 Document = new Document { Bytes = memoryStream },
10 FeatureTypes = new List<string> { "FORMS" },
11};
12
13var analyzeDocumentResponse = await TextractClient.AnalyzeDocumentAsync(analyzeDocumentRequest);
14keyValuePairs = analyzeDocumentResponse.GetKeyValuePairs();- Lines 1-5, open the file and copy it to a memory stream
- Lines 7-11, create a Textract request, setting the feature type to “FORMS”, this indicates we want to extract form data
- Line 13, make the request to Textract
- Line 14, use an extension method to extract the key-value pairs from the response
Reminder, the code here, including the extension method is for demo purposes only. If you want to do something like this in production, you need to rewrite the code to be more robust.
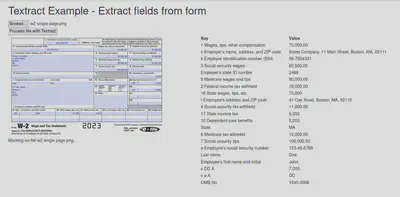
In the next post on Textract, I will show how to extract key-value pairs from a document with forms on multiple pages.
Download full source code.