Transcribing Two Speakers with Amazon Transcribe via Channel Identification
Want to learn more about AWS Lambda and .NET? Check out my A Cloud Guru course on ASP.NET Web API and Lambda.
Download full source code.
In an earlier post I showed how to use Amazon Transcribe to convert speech to text. That post showed how to upload the audio, start the transcription job, poll for completion, and download the JSON results, all with .NET. The downloaded JSON has an easy to access transcript, but if there was more than one speaker, what each speaker said would be grouped together in a single string. Transcribe did not try to identify different speakers.
It is easy to send a request to Transcribe that attempts to identify each speaker. There are two ways to do this, the first and simpler approach is to use different audio channels for different speakers. This has to be done when the audio file is created. The second is to request that Transcribe identify the speakers by analyzing the audio.
In this post, I will show how to use the first approach, where the two speakers are on different audio channels.
What I want to end up with is something like this: {{ < highlight cfg> }} 00:00:22: ch_0: blah, blah, blah. 00:00:24: ch_1: yada, yada, yada. 00:00:35: ch_0: blah, blah, blah, blah. 00:00:40: ch_1: yada, yada, yada, yada, yada. {{ < /highlight > }}
The Audio File
When I finish recording a podcast, I have two audio files, one with what I said, and one with what the guest said. I put these two files together in Audacity, where each file is on a different audio channel.
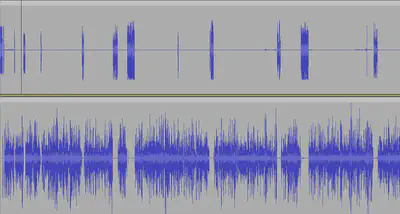
This is what the audio looks like in Audacity. The upper channel is what I said, the lower channel is what the guest said.
Then I export the audio to a stereo MP3 file.
This is the file I upload to S3, and start the Transcribe job on.
I’m not going to show the code again, you can see it in the earlier post.
But I make one change to the StartTranscriptionJobRequest. I add a Settings object, and set the ChannelIdentification property to true.
}
var startTranscriptionJobRequest = new StartTranscriptionJobRequest()
{
TranscriptionJobName = transcriptionJobName,
LanguageCode = LanguageCode.EnUS,
Settings = new Settings()
{
ChannelIdentification = true
},
Media = new Media()
{
MediaFileUri = s3Uri
},
OutputBucketName = bucketName
};The other post also showed how to download the JSON results, do that. You have the JSON and you want to get the transcript with the speakers identified.
Processing the JSON
The code here is not designed to be efficient, it is designed to be easy to understand. If you want to use this in production, I suggest you make it more efficient.
As mentioned above this code assumes you have downloaded the JSON results from S3, and that you have two channels.
The code uses a Dictionary to store the lines of dialogue, with the start time of the sentence as the key, and the Line object as the value. The line contains, among other things, what was said and the speaker’s channel label.
The outer loop iterates through the channels. The inner loop iterates through the items in the channel. The items are the words, punctuation, and timing that make up the transcript of the channel. The items are combined into lines and added to the dictionary.
using System.Text;
using System.Text.Json;
using System.Text.Json.Serialization;
var serializationOptions = new JsonSerializerOptions()
{
Converters =
{
new JsonStringEnumConverter()
},
NumberHandling = JsonNumberHandling.AllowReadingFromString
};
string jsonString = File.ReadAllText("transcription.json");
TranscriptionJob transcriptionJob = JsonSerializer.Deserialize<TranscriptionJob>(jsonString, serializationOptions);
Dictionary<double, Line> dialogue = new Dictionary<double, Line>();
StringBuilder sb = new StringBuilder();
bool startOfSentence = true;
double sentenceStartTime = 0;
foreach (var channel in transcriptionJob.Results.ChannelLabels.Channels)
{
foreach (var item in channel.Items)
{
if (startOfSentence)
{
sentenceStartTime = item.StartTime;
startOfSentence = false;
}
if (item.Type == AudioType.Punctuation)
{
sb.Remove(sb.Length - 1, 1); // remove space before punctuation
sb.Append($"{item.Alternatives[0].Content} ");
if (item.Alternatives[0].Content != ",") // anything other than a comma is an end of line
{
var line = new Line
{
Content = sb.ToString(),
StartTime = sentenceStartTime,
ChannelLabel = item.ChannelLabel
};
bool resultOfAdd = dialogue.TryAdd(sentenceStartTime, line);
if (!resultOfAdd)
{
Console.WriteLine($"Two lines with the same start time: {sentenceStartTime}");
// change the start time to avoid a duplicate key exception
dialogue.TryAdd(sentenceStartTime + 0.001, line);
}
startOfSentence = true;
sb.Clear();
}
}
else
{
sb.Append($"{item.Alternatives[0].Content} ");
}
}
}
foreach (var keyValuePair in dialogue.OrderBy(x => x.Key))
{
var timeSpan = TimeSpan.FromSeconds(keyValuePair.Key);
Console.WriteLine($"{timeSpan.ToString(@"hh\:mm\:ss")}: {keyValuePair.Value.ChannelLabel}: {keyValuePair.Value.Content}");
}There are a few more classes that are used in the code above, models for the JSON, and the Line class. You can see the complete code in the attached zip.
In a follow-up post, I will show how to use the second approach, where Transcribe identifies the speakers by analyzing the audio. The JSON output is different, and the code to process it is different.
Download full source code.